01. SELECT
조회하기
1) 주요 용어
- 테이블(Table) : 행과 컬럼으로 이뤄져 있는 것
- 행(Row) : 가로열
- 컬럼(Colunn) : 세로열
- 기본키(Primary Key) : 중복되지 않고 행을 구분할 수 있는 것. 줄여서 pk라고 부른다
- 외래키(Foreign Key) : 외부 테이블의 PK를 가져온 키. 참조키라고 부름
- NULL : Java에서는 참조하는게 없다. DB에서는 데이터가 없다.
- 컬럼값 : 테이블 한 칸에 작성된 값
2) SQL(Structured Query Language)
- 관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어
- 원하는 데이터를 찾는 방법이나 절차를 기술하는 것이 아닌 조건을 기술하여 작성한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
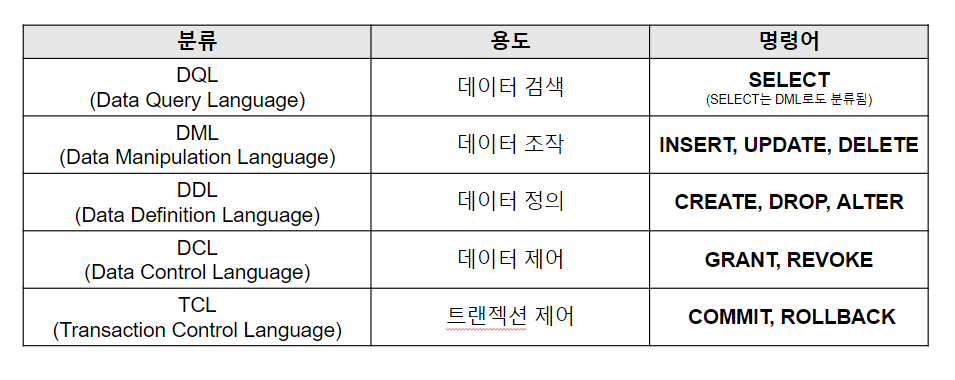
✔ DQL(/*질의어*/)
- SELECT : --테이블에 저장된 데이터를 조회하는데 사용되는 가장 기본적인 문법이고 가장 많이 사용됨
✔ DML(/*데이터 조작어*/)
- CRUD
-- 데이터를 삽입, 변경, 삭제. 즉, 조작하는 역할을 하는 명령어. INSERT, UPDATE, DELETE
✔ DDL(/*데이터정의어*/) -- 테이블과 관련됨
-- 데이터 베이스 객체들을 생성, 변경, 제거시 사용
- CREATE, ALTER, DROP, RENAME, TRUNCATE
- CREATE : /* 새로운 테이블 생성 */
- ALTER : /* 기존의 테이블을 변경함(컬럼을 추가하거나 변경) */
- RENAME : /* 테이블의 이름을 변경 */
- TRUNCATE : /* 테이블을 잘라냄(테이블 내의 저장된 내용 삭제) */
- DROP : /* 기존의 테이블을 삭제(테이블의 구조 자체를 제거)*/
✔ DCL
- GRANT : /* 권한을 주고 */
- REVOKE : /* 권한을 뺏고 */
✔ TCL(/* 트랜잭션 제어언어 */)
-- 데이터의 일관성을 유지하면서 안정적으로 데이터를 복구시키기 위해 사용
-- 여러개의 DML명령문들을 하나의 작업단위로 묶어 놓은 집합이다
-- 실수 없이 완벽하게 입력한 명령어만 영구 저장하기 위해 사용
- COMMIT : /*변경된 내용을 영구 저장 */
- ROLLBACK : /* 변경되기 이전 상태로 되돌림 */
- SAVEPOINT : /* 특정 위치까지를 영구 저장 혹은 이전 상태로 돌리기 위해 저장점을 만듦 */
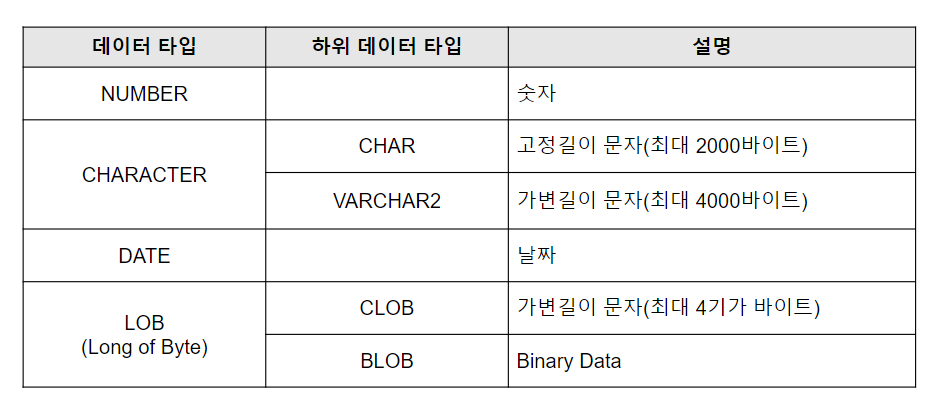
3) 주요 데이터 타입
4) SELECT
1
2
[ 작성법 ]
SELECT 컬럼명 FROM 테이블명;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
< /*컬럼 값 산술 연산*/ >
SELECT SALARY , SALARY * 12 FROM EMPLOYEE;
-- 월급, 연봉(월급 * 12)
< /*날짜 + 산술연산 (+ -)*/ >
SELECT SYSDATE - 1 , SYSDATE, SYSDATE + 1 FROM DUAL;
-- 날짜에 +/- 연산 시 일 단위로 계산이 진행된다
< /*컬럼 별칭 지정*/ >
-- 컬럼명 AS 별칭 : 별칭 띄어쓰기X, 특수문자X, 문자만O
-- 컬럼명 AS "별칭" : 별칭 띄어쓰기O, 특수문자O, 문자O
-- AS는 생략 가능
SELECT SYSDATE - 1 "하루 전" , SYSDATE AS "현재시간" , SYSDATE + 1 "내일"
FROM DUAL;
-- SELECT 조회 결과의 집합인 RESULT SET에 출력되는 컬럼명을 지정한다
< /*리터럴*/ >
-- JAVA : 값 자체를 의미
-- DB : 임의로 지정한 값을 기존 테이블에 존재하는 값처럼 사용
[ /*표기법*/ ] ' ' /*홑따옴표*/
SELECT EMP_NAME , SALARY, '원 입니다' FROM EMPLOYEE;
< DISTINCT >
-- 조회 시 컬럼에 포함된 중복 값을 한 번만 표기
-- 주의사항 1) DISTINCT 구문은 SELECT마다 딱 한번만 작성
-- 2) DISTINCT 구문은 SELECT 제일 앞에 작성
SELECT DISTINCT DEPT_CODE , JOB_CODE FROM EMPLOYEE;
-- 두 개의 컬럼일 때는 두개를 묶어서 하나의 값으로 본다
1
2
3
4
5
6
7
/*
< 해석 순서 >
3.SELECT 절 : SELECT 컬럼명
1.FROM 절 : FROM 테이블명
2.WHERE 절(조건절) : WHERE 컬럼명 연산자 값;
4.ORDER BY 컬럼명 | 별칭 | 컬럼 순서 [ASC | DESC][NULLS FIRST | LAST]
*/
5) 연산자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
< /*논리 연산자 (AND, OR)*/ >
SELECT EMP_ID , EMP_NAME , SALARY
FROM EMPLOYEE
WHERE SALARY < 3000000 OR SALARY >= 5000000;
-- 월급 300만 미만 또는 500만 이상
SELECT EMP_ID , EMP_NAME , SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY < 5000000;
-- 월급 300만 이상, 500만 미만
SELECT EMP_ID , EMP_NAME , SALARY
FROM EMPLOYEE
WHERE SALARY BETWEEN 3000000 AND 5000000;
-- 월급 300만 이상, 500만 이하
SELECT EMP_ID , EMP_NAME , SALARY
FROM EMPLOYEE
WHERE SALARY NOT BETWEEN 3000000 AND 5000000;
-- 월급 300만 미만, 500만 초과 (300~500사이 제외)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
< LIKE >
-- 비교하려는 값이 특정한 패턴을 만족 시키면 조회하는 연산자
[/*작성법*/]
WHERE'컬럼명' LIKE '패턴이 적용된 값'
-- LIKE의 패턴을 나타내는 문자(와일드 카드)
--> '%' : 포함
--> '\_' : 글자 수
-- '%' 예시
-- 'A%' : A로 시작하는 문자열
-- '%A' : A로 끝나는 문자열
-- '%A%' : A를 포함하는 문자열
-- '\_' 예시
-- 'A__' : A로 시작하는 두글자 문자열
-- '\_\_\_A' : A로 끝나는 4글자 문자열
-- '\_\_A\_\_' : 세 번째 문자가 A인 다섯글자 문자열
-- '\_\_\_\_\_' : 5글자 문자열
SELECT EMP_ID , EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME LIKE '전%';
-- 전씨 성을 가진 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE PHONE NOT LIKE '010%';
-- 전화번호가 010으로 시작하지 않는 사원의 사번, 이름 조회
1
2
3
4
5
6
7
8
9
10
11
12
13
< ESCAPE >
-- #, ^ 를 많이 씀
-- ESCAPE 문자 뒤의 '\_'는 일반 문자로 탈출한다는 뜻
SELECT EMP-ID, EMP_NAME
FROM EMPLOYEE
WHERE EMAIL LIKE ____%;
--> 원하는 값 도출X
SELECT EMP-ID, EMP_NAME
FROM EMPLOYEE
WHERE EMAIL LIKE ___#_% ESCAPE '#';
--> \_를 기준으로 앞에 3글자인 EMAIL을 가진 사원의 사번, 이름 조회
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- < 연습 문제 !!! >
-- EMPLOYEE 테이블에서
-- 이메일 '\_'앞이 4글자 이면서
-- 부서 코드가 'D9' 또는 'D6'이고 -> AND가 OR 보다 우선순위가 높다, ()사용가능
-- 입사일이 1990-01-01 ~ 2000-12-31 이고
-- 급여가 270만 이상인 사원의
-- 사번, 이름, 이메일, 부서보드, 입사일, 급여 조회
SELECT EMP_ID, EMP_NAME, EMAIL, DEPT_CODE, HIRE_DATE, SALARY
FROM EMPLOYEE
WHERE EMAIL LIKE '\_\_\_\_#\_%' ESCAPE '#'
AND (DEPT_CODE = 'D9' OR DEPT_CODE = 'D6')
AND HIRE_DATE BETWEEN '1990-01-01' AND '2000-12-31'
AND SALARY >= 2700000;
1
2
3
4
5
6
7
8
9
10
< 연산자 우선순위 >
1. 산술연산자(+ - * / )
2. 연결연산자( || )
3. 비교연산자( > < >= <= = != <> )
4. IS NULL / IS NOT NULL, LIKE, IN / NOT IN
5. BETWEEN AND / NOT BETWEEN AND
6. NOT(논리연산자)
7. AND(논리연산자)
8. OR (논리연산자)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- < IN 연산자 >
-- 비교하려는 값과 목록에 작성된 값 중 일치하는 것이 있으면 조회하는 연산자
-- [작성법]
WHERE '컬럼명' IN('값1', '값2', '값3'...)
(= WHERE '컬럼명' = '값1' OR '컬럼명' = '값2' OR '컬럼명' = '값3';)
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE IN('D1','D6','D9');
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE NOT IN('D1','D6','D9')
OR DEPT_CODE IS NULL;
-- D1, D6, D9를 제외한 부서 + 부서가 NULL값인 사원
1
2
3
4
5
6
7
8
9
10
11
12
< IS NULL / IS NOT NULL >
-- NULL 처리 연산자
-- JAVA에서 NULL : 참조하는 객체가 없음을 의미
-- DB에서 NULL : 컬럼에 값이 없음을 의미
-- IS NULL : NULL인 경우 조회
-- IS NOT NULL : NULL이 아닌 경우 조회
SELECT EMP_NAME, BONUS
FROM EMPLOYEE
WHERE BONUS IS NOT NULL;
6) ORDER BY
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
< ORDER BY >
-- ORDER BY 절 : 정렬과 관련
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY;
-- 급여를 기준으로 오름차순 정렬(기본값)
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC;
-- 급여를 기준으로 내림차순 정렬
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY 3 DESC;
-- 컬럼명 대신 컬럼의 순서를 명시(여기서는 SALARY가 3번째)
SELECT EMP_ID `이름`, HIRE_DATE `입사일` -- AS 생략
FROM EMPLOYEE
ORDER BY `입사일`;
-- 컬럼명 대신 별칭 사용
-- < 정렬 중첩 >
-- ',' 사용
-- 정렬 중첩 : 대분류 정렬 후 소분류 정렬
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE , SALARY DESC;
-- 부서별로 오름차순 후, 그 안에서 급여별 내림차순 정렬