10. Collection
컬렉션
1) 정의
- 메모리상에서 자료를 구조적으로 처리하는 방법을 자료구조라 일컫는데 컬렉션(collection)은 자바에서 제공하는 자료구조를 담당하는 프레임워크
- 추가, 삭제, 정렬 등의 기능처리가 간단하게 해결 되어 자료구조적 알고리즘을 구현할 필요 없음
2) 자료구조 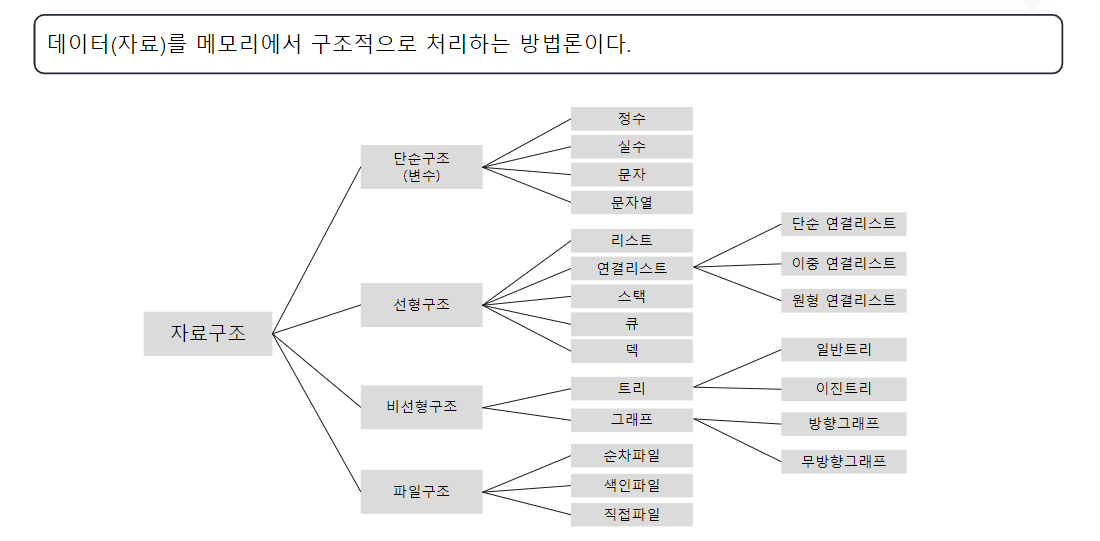
3) 배열의 문제점 & 컬렉션의 장점
- 배열의 문제점
- 한 번 크기를 지정하면 변경할 수 없다.
- 공간 크기가 부족하면 에러가 발생 -> 할당 시 넉넉한 크기로 할당하면 메모리가 낭비됨
- 필요에 따라 공간을 늘리거나 줄일 수 없음
- 배열에 기록된 데이터에 대한 중간 위치의 추가, 삭제가 불편하다
- 추가, 삭제할 데이터부터 마지막 기록된 데이터까지 하나씩 뒤로 밀어내고 추가해야 함 ( 복잡한 알고리즘 )
- 한 타입의 데이터만 저장 가능하다
- 한 번 크기를 지정하면 변경할 수 없다.
- 컬렉션의 장점
- 저장하는 크기의 제약이 없다
- 추가, 삭제, 정렬 등의 기능 처리가 간단하게 해결된다
- 자료를 구조적으로 처리 하는 자료구조가 내장되어 있어 알고리즘 구현이 필요 없음
- 여러 타입의 데이터가 저장 가능하다
- 객체만 저장할 수 있기 때문에 필요에 따라 기본 자료형을 저장해야 하는 경우 Wrapper 클래스 사용
- Wrapper 클래스
- ⓐBoolean ⓑCharacter ⓒByte ⓓShort ⓔInteger ⓕLong ⓖFloat ⓗDouble
(Ex) “10” -> Integer.parseInt(“10”) -> 10
“13.45” -> Double.parseDouble(“13.45”) -> 13.45
- ⓐBoolean ⓑCharacter ⓒByte ⓓShort ⓔInteger ⓕLong ⓖFloat ⓗDouble
1 2 3 4 5
<배열과 컬렉션의 차이점> 1. 배열은 크기를 지정해야 하고, 한 번 지정된 크기 변경이 불가능하지만 컬렉션은 크기에 제약이 없다. 2. 배열은 중간에 값을 추가, 삭제, 정렬 할 때 개발자가 직접 코드로 로직을 짜야한다. 하지만 컬렉션에서는 이미 자료구조적인 알고리즘이 내장되어 있어 메소드 호출만으로 데이터를 효율적, 구조적 관리 가능하다. 3. 배열은 한가지 타입의 여러개 데이터를 보관할 수 있다면, 컬렉션은 별도의 제네릭설정을 하지 않을 경우 여러타입의 여러개의 데이터 보관 가능하다.
4) 컬렉션의 주요 인터페이스 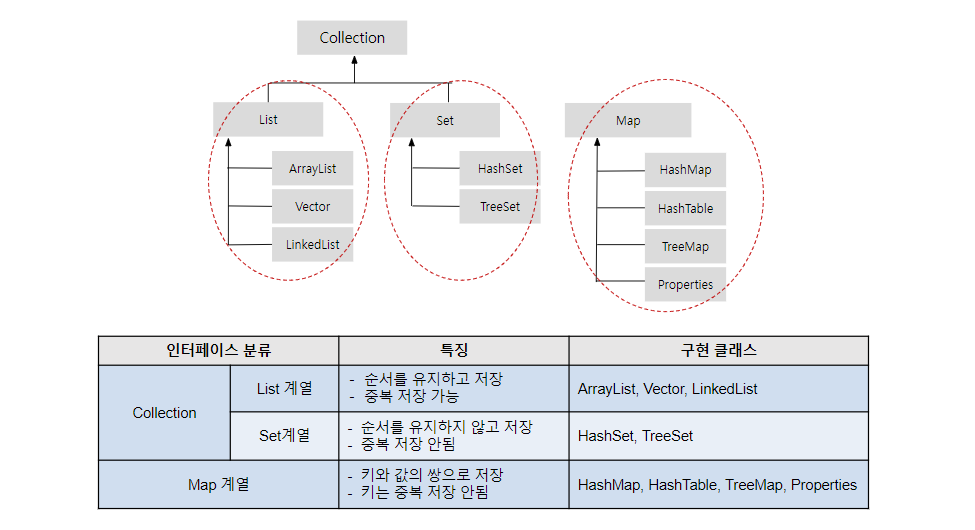
- 인터페이스 : 접점. 관련 없는 것들의 연결, 공통된 메소드명을 제공하여 규약을 만듦
- Java Collection : 자바의 자료구조 모음 (List, Set, Map)List, Set의 중복 코드를 뽑아서 만든 인터페이스 Collection( 부모 인터페이스의 인터페이스명이다)
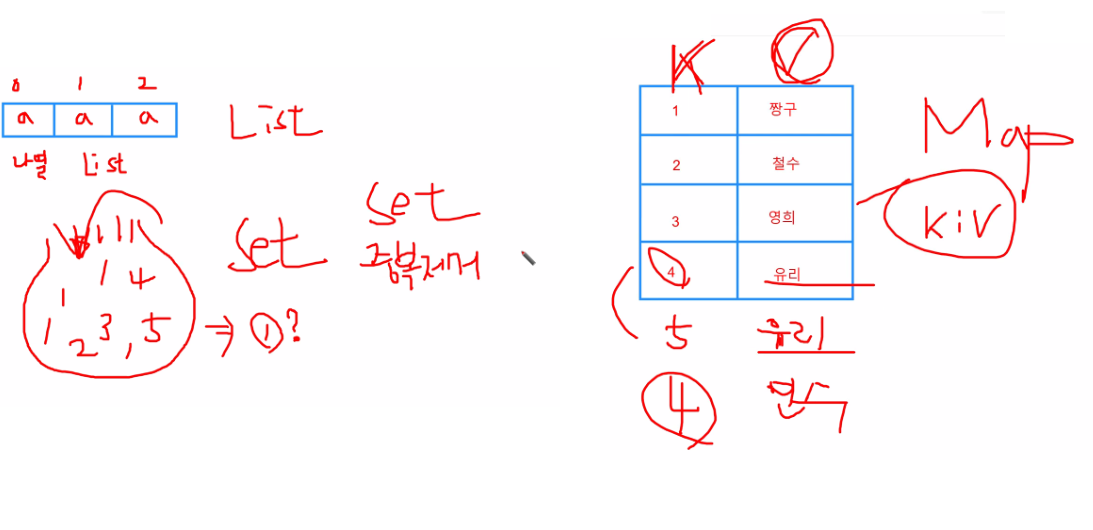
- List는 각각의 인덱스 번호가 있기 때문에 같은 값이라도 구분이 가능
- Set은 한주머니 안에 데이터가 들어가 있기 때문에 어떤 데이터가 나왔을 때 출처를 모른다. 그래서 중복제거를 시행한다
- Map은 Key를 부르면 value가나오는 형태, 데이터의 중복은 허용하지만 키의 중복은 허용하지 않는다.
5) List
- 자료들을 순차적으로 나열한 자료구조로 인덱스로 관리되며, 중복해서 객체 저장 가능.
- 구현 클래스로 ArrayList와 Vector, LinkedList가 있음
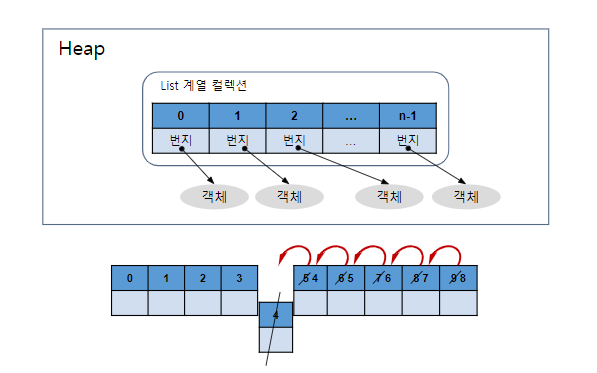
- 구현 클래스로 ArrayList와 Vector, LinkedList가 있음
List 계열 주요 메소드

- ArrayList
- List의 후손을 초기 저장 용량은 10으로 자동 설정되며 따로 지정도 가능하다
- 저장 용량을 초과한 객체들이 들어오면 자동으로 늘어나며 고정도 가능
동기화(Synchronized)를 제공하지 않음
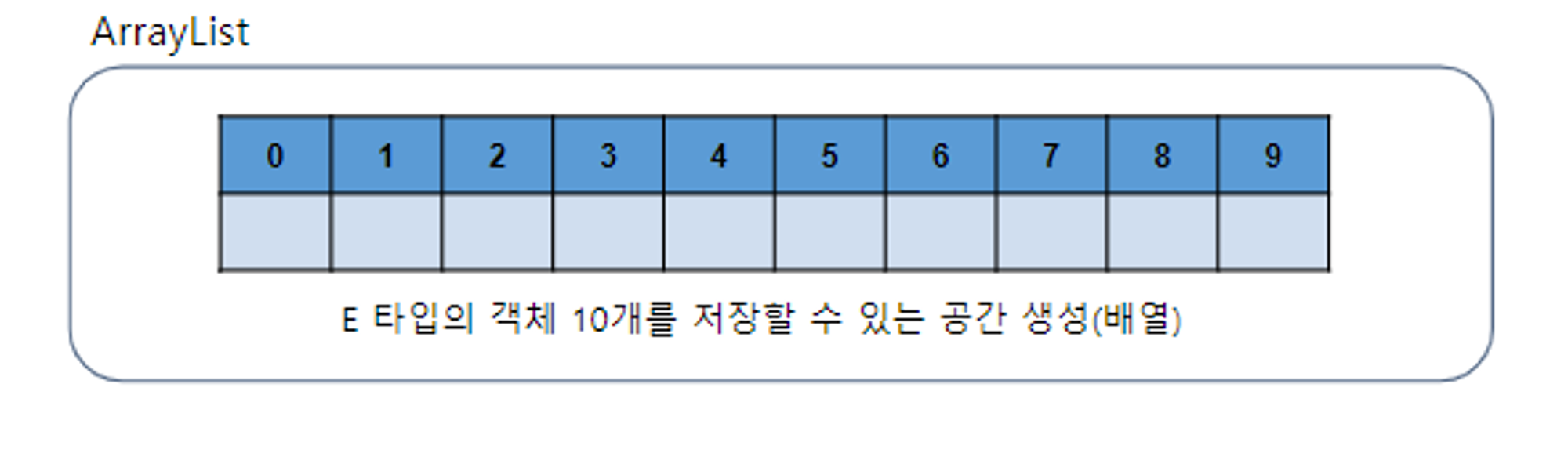
- 동기화 : 한번에 한가지 일만 수행
- 비동기화 : 동시에 일을 수행

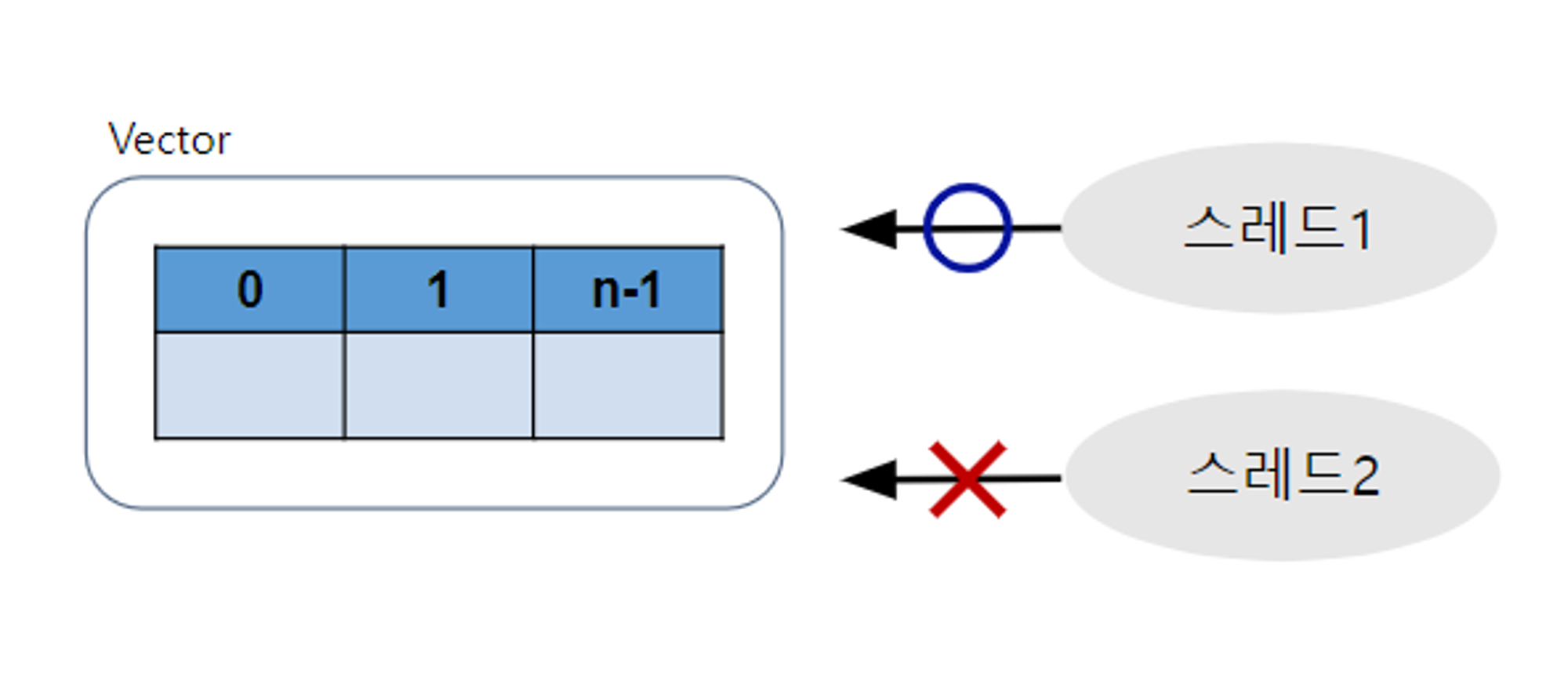
- Vector
- List의 후손
- ArrayList와 동등하지만 동기화를 제공한다는 점이 ArrayList와 차이점 -> List 객체들 중에서 가장 성능이 좋지 않음
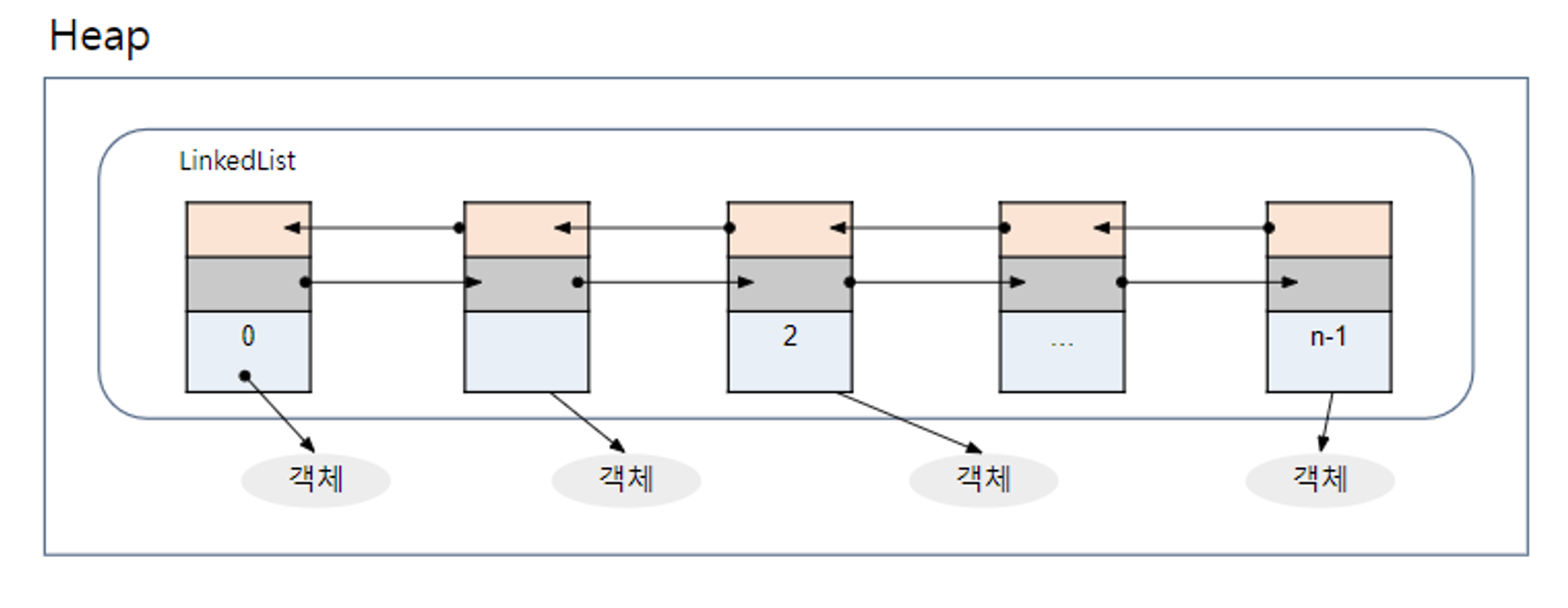
- LinkedList
- List의 후손으로, 인접 참조를 링크해 체인처럼 관리
- 특정 인덱스에서 객체를 제거하거나 추가하x`게 되면 바로 앞/뒤 링크만 변경하면 되기 때문에 삭제와 삽입이 빈번하게 일어나는 곳에서 ArrayList보다 성능이 좋다
- ArrayList
6) Set
- 저장 순서가 유지되지 않고, 중복 객체도 저장하지 못하게 하는 자료 구조
- null도 중복을 허용하지 않고, 1개만 저장
구현 클래스 : HashSet, LinkedSet, TreeSet
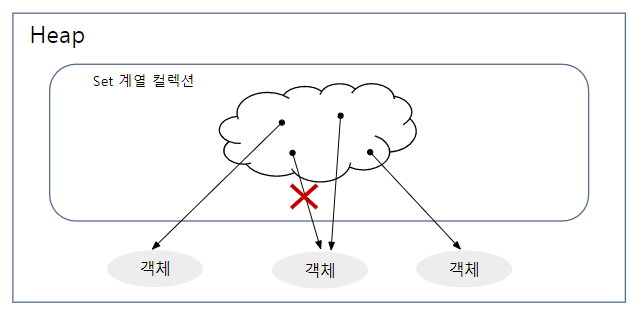
- Set 계열 주요 메소드
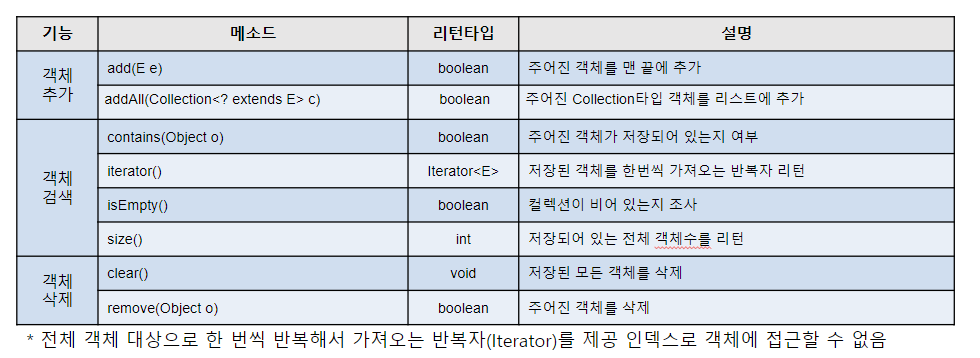
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
< HashSet >
Set에 객체를 저장할 때 hash함수를 사용하여 처리 속도가 빠름.
동일 객체 뿐 아니라 동등 객체도 중복하여 저장하지 않음
< LinkedHashSet >
HashSet과 거의 동일하지만 Set에 추가되는 순서를 유지
< TreeSet >
순서를 유지하지는 않지만 오름차순으로 자동 정렬한다
(1)Set<Integer> lotto = new HashSet<Integer>();
(2)Set<Integer> lotto = new LinkedHashSet<Integer>();
(3)Set<Integer> lotto = new TreeSet<Integer>();
while(lotto.size() < 6) {
int randome = (int)( Math.random() * 45 + 1 );
System.out.print(random + ", ");
lotto.add(random);
}
System.out.println(lotto);
출력 값
random : 21, 15, 4, 15, 14, 25, 37
(1) [4, 21, 37, 25, 14, 15]
(2) [21, 15, 4, 14, 25, 37]
(3) [4, 14, 15, 21, 25, 37]
7) Map
- 키(Key)와 값(Value)으로 구성되어 있으며, 키와 값은 모두 객체
- 키는 중복 저장을 허용하지 않고(Set방식), 값은 중복 저장 가능(List방식)
- 키가 중복되는 경우, 기존 키의 값에 해당하는 값을 덮어 씌움
구현 클래스 : HashMap, HashTable, LinkedHashMap, TreeMap
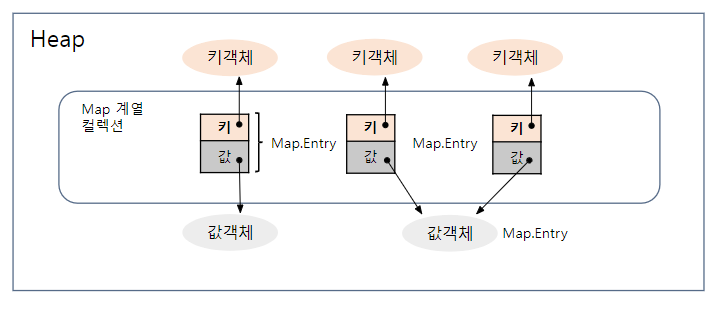
Map 계열 주요 메소드
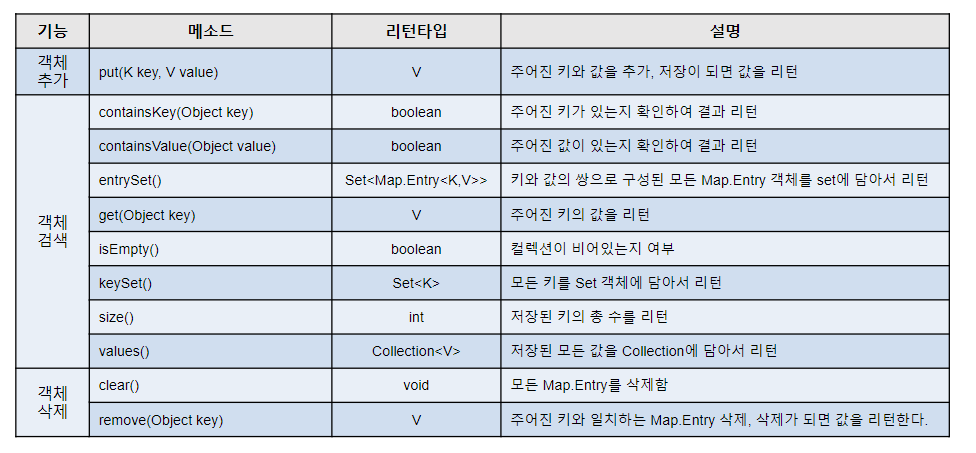
- Map에 담겨있는 요소들에 순차적으로 접근하기 위한 2가지 방법
1_ keySet() 이용하기 : keySet() 으로 Map의 Key를 Set에 담은 후 Set에 있는 Iterator를 통해 접근1 2 3 4
for(String key : map.keySet()) { Object value = map.get(key); System.out.println(key + " : " + value); }
2_ entrySet() 이용하기 : entrySet()으로 Map의 key와 value를 Set에 담은 후 Set에 있는 Iterator를 통해 접근
1 2 3
for(Map.Entry<String, Integer> temp : empMap.entrySet()) { System.out.println(temp); }
8) 정리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
< List Interface >
- ArrayList : 상대적으로 빠르고 요소에 대해 순차적으로 접근할 수 있다.
- Vector : ArrayList의 이전 버전이며 모든 메서드가 동기화 되어 있다.
- LinkedList : 순서가 변경되는 경우 노드 링크만 변경하면 되므로 삽입, 삭제가 빈번 할 때 빠르다.
< Set Interface >
- HashSet : 빠른 접근 속도를 가지고 있으나 순서를 예측할 수 없다.
- LinkedHashSet : 요소가 추가된 순서대로 접근할 수 있다.
- TreeSet : 요소들의 정렬 방법을 직접 지정할 수 있다.
< Map Interface >
- HashMap : 중복을 허용하지 않고 순서를 보장하지 않으며 null 값을 허용한다.
- Hashtable : HashMap 보다는 느리지만 동기화를 지원하며 null 값을 허용하지 않는다.
- TreeMap : 정렬된 순서대로 Key와 Value를 저장하므로 빠른 검색이 가능하지만 요소를 추가할 때 정렬로 인해 오래걸린다.
- LinkedHashMap : HashMap과 기본적으로 동일하지만 입력한 순서대로 접근이 가능하다.