Redis 소개
- 레디스는 메모리 기반의 데이터 저장소이다.
- 키-벨류(key-value) 데이터 구조에 기반한 다양한 형태의 자료 구조를 제공하며, 데이터들을 저장할 수 있는 저장소이다
- 레디스는 메모리에 데이터를 저장하기 때문에 저장 공간에 제약이 있어, 주로 보조 데이터 저장소로 사용한다
- 이를 극복하기 위해 레디스 클러스터 기능을 제공하고 있어 저장 공간을 확장할 수 있다
- 또한 저장된 데이터를 영구적으로 디스크에 저장할 수 있게 백업 기능을 제공한다
- 메모리에 데이터를 저장하기 때문에 빠른 처리 속도가 장점이다.
- 레디스 내부에서 명령어를 처리하는 부분은 싱글 스레드 아키텍처로 구성되어 있다.
- 멀티 스레드 아키텍처보다 구조가 단단하게 설계되어 여러 장점이 있다.
- 정리하면 장점은 빠른 처리 속도, 단점은 저장 공간 제약이다.
Redis 데이터 백업 방식
- 메모리에서 데이터를 관리하므로 빠른 속도로 데이터를 저장 및 조회할 수 있다.
- 하지만 메모리 특성상 저장된 데이터는 소실될 가능성이 있다. (휘발성)
- 이를 보완하고자 레디스는 데이터에 영속성을 제공한다
- 즉, 메모리의 데이터를 디스크에 백업하는 기능을 제공하는 것이다.
RDB ( snapshot )
- 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크에 저장하는 방식
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 데이터를 복원해야 한다면 스냅샷 파일을 그대로 로딩만 하면 된다
- 하지만, 스냅샷 이후에 변경된 데이터는 복구할 수가 없다. 데이터 유실
AOF ( Append Only File )
- 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식
- 데이터를 생성, 수정, 삭제하는 이벤트를 초 단위로 취합 및 로그 파일에 작성한다
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능하다
- RDB 방식에 비해 데이터 유실량이 적다. (초 단위 데이터는 유실 가능)
- RDB 방식보다 로딩 속도가 느리고 war 파일 크기가 큰 것이 단점이다
선택
- 일부 데이터 손실에 영향을 받지 않는 경우(캐시로만 사용할 때)
- 장애 상황 직전까지의 모든 데이터가 보존되어야 하는 경우
- 강력한 내구성이 필요한 경우
- 일반적으로 AOF 와 RDB 를 동시에 사용한다
- 매일 7시마다 RDB 스냅샷을 생성하고, RDB 생성 이후에 변경되는 데이터는 AOF로 백업한다
Redis 백업 방식 설정
RDB
- 자동 : Redis.conf 파일 → SAVE 옵션 설정 (시간 기준)
- 수동 : redis-cli 에서 BGSAVE 커맨드를 이용하여 수동으로 RDB 파일 저장
- SAVE 커맨드는 절대 사용 X (레디스는 싱글 스레드, 저장하는 동안 다른 작업 수행 불가)
AOF
- 자동 : redis.conf 파일 → auto-aof-rewrite-percentage 옵션 설정 (크기 기준)
- 수동 : redis-cli 에서 BGREWRITEAOF 커맨드를 이용하여 수동으로 AOF 파일 재작성
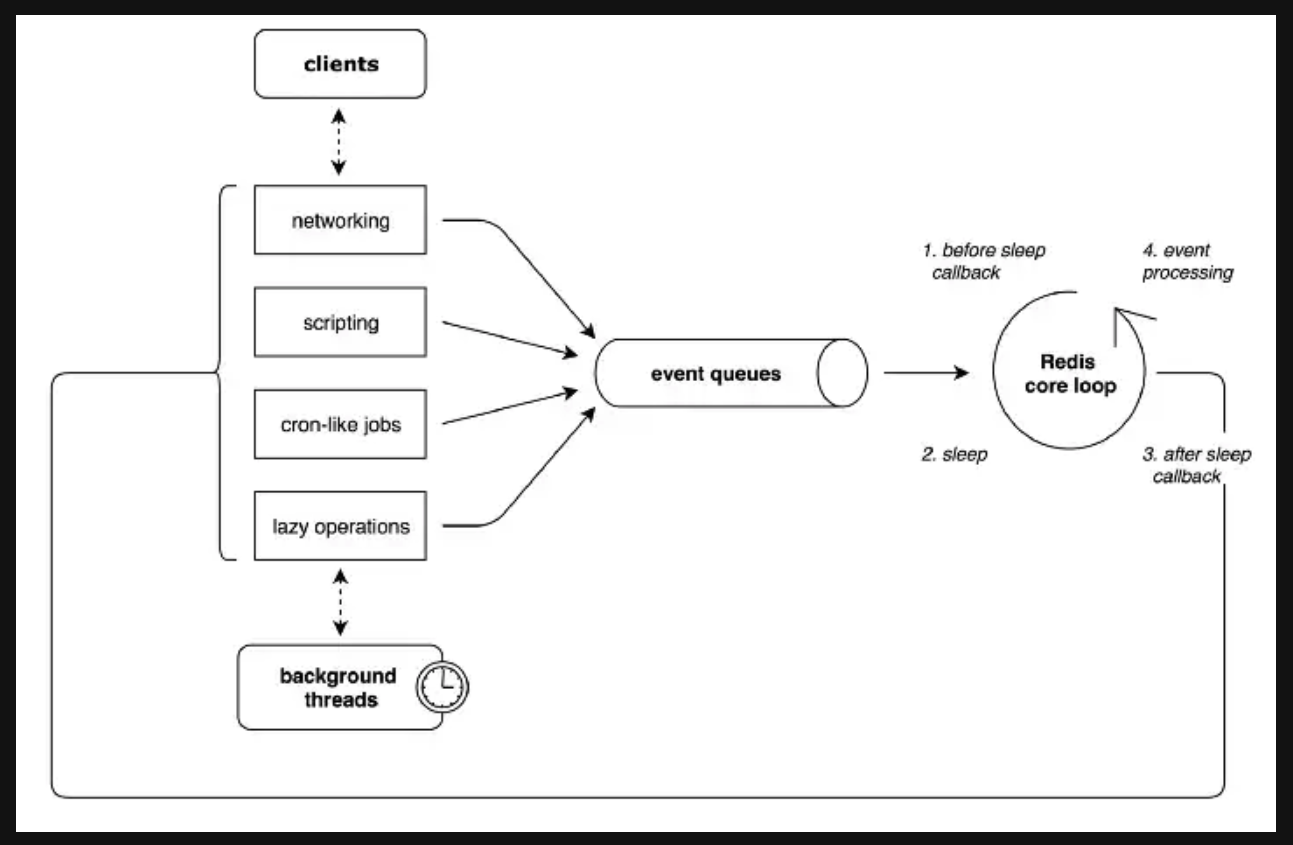
Redis single thread
레디스의 코어스레드는 싱글스레드
- 레디스는 사용자들이 실행한 명령어들을 이벤트 루프(event loop) 방식으로 처리한다.
- 클라이언트가 실행한 명령어들을 Event Queue에 적재하고 싱글 스레드로 하나씩 처리한다
- 메모리를 사용하기 때문에 싱글 스레드로 데이터를 빠르게 처리할 수 있다
- 장점
- 멀티 스레드 환경이 아니라 Context Switch 발생 X → 효율적인 시스템 리소스 사용이 가능하다
- 위와 같은 이유로 Deadlock이 발생하지 않는다
- 단점
- 싱글 스레드라서 전체 데이터 스캔과 같은 오버헤드가 큰 명령어를 처리하는 동안 다른 명령어 처리가 불가능 하다
- 이 때, 다른 명령어들이 Queue에 저장되어 있는 시간이 길어진다 → 응답 속도 저하
Redis 사용 용도
- 주 데이터 저장소
- AOF, RDB 백업 기능과 레디스 아키텍처를 사용하여 주 저장소로 데이터를 저장할 수 있다.
- 하지만 메모리 특성상 용량이 큰 데이터 저장소로는 부적합하다
- 데이터 캐시
- 인메모리 데이터 저장소이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터를 읽을 수 있다
- 캐시된 데이터는 한 곳에 저장되는 중앙 집중형 구조로 구성한다 → 데이터 일관성 유지 가능
- 분산 락(distributed lock)
- 분산 환경에서 여러 시스템들이 동시에 데이터를 처리할 때는 특정 공유 자원의 사용 여부를 검증하여 데드 락을 방지할 필요가 있다
- 이때 레디스를 분산 락으로 사용할 수 있다
- 순위 계산
- 레디스에서 제공하는 ZSet(Sorted Set) 자료 구조를 이용하여 순위 계산 용도로 사용하기도 한다
- ZSet은 정렬 기능이 포함된 Set 자료 구조이므로 쉽고 빠르게 순위를 계산할 수 있다
Redis 아키텍처
- 레디스는 3가지 아키텍처로 나누어 볼 수 있다
1. Replication 아키텍처
- Master 와 Replica 로 구성
- 단순한 복제 연결 시 사용한다 (relicaof 커맨드 이용)
- 비동기식 복제 (복제가 잘 됐는지 확인하지 않음)
- HA(고가용성) 기능이 없으므로 장애 상황 시 수동으로 복구해야 한다
- 장애 상황 시 스프링에서 새로운 Redis 서버의 연결 정보를 변경해주어야 한다
2. Sentinel 아키텍처
- Sentinel, Master, Replica 로 구성
- 자동 Failover 가 가능한 고가용성 구성
- 레디스 센티넬은 레디스 서버들(Master, Replica)를 관리한다.
- 센티넬은 주기적으로 레디스 서버들을 모니터링 하다가, 마스터 서버가 서비스할 수 없는 상태가 되면 다른 레플리카를 마스터 서버로 변경한다
- Sentinel 노드가 Redis 마스터와 레플리카 노드를 감시
- 마스터가 비정상 상태일 때 자동으로 Failover(자동복구)가 실행
- 애플리케이션은 Sentinel 과 연결하기 때문에, 장애 발생 시 연결 정보를 변경할 필요가 없다
- Sentinel 노드도 장애 상황이 발생할 수 있기 때문에 반드시 3대 이상의 홀수로 존재해야 한다
- 과반수 이상의 Sentinel이 동의(Quorum based)가 있어야 Failover가 진행된다
- 많은 리소스가 필요하므로 Sentinel과 Master 혹은 Replica를 같은 서버에 올려 사용하기도 한다
3. Cluster 아키텍처
- 레디스 3.0 버전 이후부터 제공된다
- 클러스터에 포함된 노드들이 서로 통신하며 고가용성을 유지한다.
- 샤딩 기능까지 기본 기능으로 사용할 수 있다
- 샤딩 : 큰 데이터를 분산 저장하는 데이터 처리 기법
- 클러스터 내부에는 센티넬과 동일하게 마스터와 레플리카는 짝을 이루어 데이터를 복제한다
- 클러스터 내부의 모든 노드는 모두 서로 연결되어 있는 메쉬(Mesh) 구조로 되어 있으며, 가십 프로토콜(gossip protocol)을 사용하여 서로 모니터링 한다
- 센티넬과 동일하게 마스터와 레플리카는 짝을 이루어 데이터를 복제한다
- 클러스터를 구성하기 위해 세 개의 마스터 노드는 반드시 필요하다
- 레플리카 노드의 개수는 0개 혹은 그 이상으로 설정 가능하다
- 고가용성을 위해 반드시 한 개 이상의 레플리카를 설정하는 것이 좋다
- 데이터를 마스터 노드들에 샤딩
- 해시 함수를 사용하여 데이터 분배, 데이터의 키 값을 해시 함수로 넘긴 후 리턴 값을 사용하여 어떤 노드에 저장할지 결정한다
- 클러스터에 노드를 추가하거나 제거할 경우 레디스 명령어를 사용하여 해시 함수 값 범위를 조정 가능
- 리밸런싱(Re-balancing) & 리샤딩(Re-Shard)
- 조정된 범위에 포함되는 레디스 데이터들은 자동으로 재분배 되어 설정된 위치로 이동한다
- 애플리케이션은 레디스 클러스터의 노드 중 하나라도 연결되면 클러스터의 전체 상태 정보를 확인 가능하다
- 장애 상황 발생 또는 노드 확장 시 애플리케이션의 Redis 서버 연결 정보 필요 없다
참고 사이트
banggeunho.log